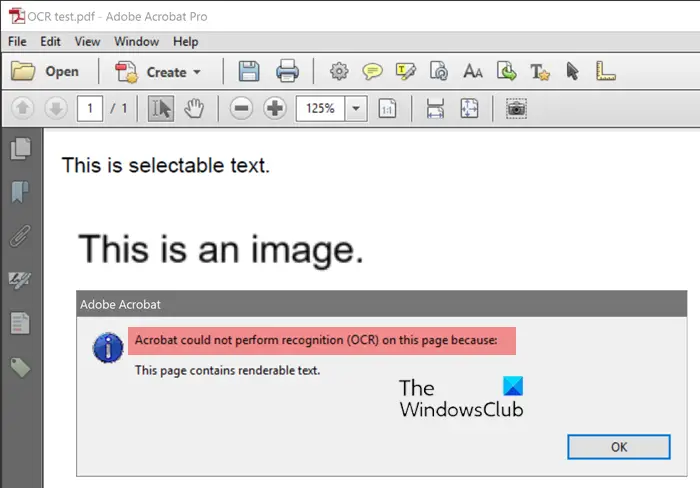
光学式文字認識 (OCR)テキストのページを編集可能なテキストに変換する必要がある人にとっては、スライスしたパンよりも優れているかもしれません。スキャンして PC に取り込んだテキストのページがある場合、それを編集可能な形式に変換する必要があるかもしれません。入力する時間が足りないか、入力する時間が多すぎるのかもしれません。光学式文字認識はまさにそれを助けることができます。ページをスキャンしてコンピュータに取り込み、次のコマンドで開くことができます。アドビアクロバットOCR 機能を使用してテキストを認識し、編集可能なバージョンを取得してみます。勝利のダンスをしようとしたときにエラーが発生しますこのページにはレンダリング可能なテキストが含まれているため、Acrobat はこのページで認識 (OCR) を実行できませんでした。
Adobe OCR がテキストを認識しない
Acrobat Professional には OCR 機能があり、スキャンした文書をリッチテキスト形式または Microsoft Word 文書 (Doc と Docx の両方) として保存できます。 Adobe Acrobat professional で文書を開くと、テキストは表示されますが、Acrobat でエラーが発生する場合があります。 Acrobat はテキストに対して OCR を使用できません。これにはいくつかの理由が考えられます。
- レンダリング可能/編集可能なテキスト
- 歪んだ、またはぼやけたソース
- 低品質のオリジナル
- グラフィックとフォーム
このページにはレンダリング可能なテキストが含まれているため、Acrobat はこのページで認識 (OCR) を実行できませんでした。
1] レンダリング可能/編集可能なテキスト
レンダリング可能なテキストは、OCR を実行するファイル内に存在する編集可能なテキストです。 Acrobat は、表示可能なテキストを含むドキュメントに対して OCR を実行できません。私たちは常に、読み取り可能なテキストは OCR でもスキャンできるはずだと想定しているため、これは OCR スキャン エラーの最も明らかな理由ではありません。
解決:
これに問題がある場合、エラーに対処する方法は 2 つあります。
- 表示可能なテキストが含まれていないドキュメントのコピーを取得してみてください。
- PDF を TIFF に変換してから PDF に戻し、OCR を再試行します。
PDF を TIFF に変換するには、Acrobat で開き、「ファイル」、「名前を付けて保存」の順に選択します。 [名前を付けて保存] ダイアログ ボックスが表示されたら、[名前を付けて保存] の種類から TIFF (*.tif、*.tiff) を選択します。ファイルを保存する場所を指定し、「保存」をクリックします。 Acrobat は、PDF ドキュメントの各ページを、連続番号が付けられた個別の TIFF ファイルとして保存します。次に、各 TIFF ファイルを開き、Acrobat を使用して OCR を実行します。
ドキュメントを 1 つに結合する場合は、次の手順を実行します。
- Acrobatを開き、選択しますファイルそれからPDFの作成それから複数のファイルから。
- 選択ブラウズをクリックして、各 PDF ファイルを選択して追加します。新しい PDF に表示されるようにファイルを再配置します。
- 選択わかりました。
2] 歪みまたはぼやけたソース
ぼやけた文書
Acrobat がドキュメントに対して OCR を実行できないもう 1 つの理由は、ドキュメントの解像度が低い場合です。低解像度のドキュメントはぼやける可能性があり、Acrobat は OCR を実行できません。
解決:
ドキュメントの高解像度ソースを入手します。紙の文書からスキャンする場合は、より高解像度のスキャンが行われるようにスキャナーの解像度を調整します。
歪んだ文書
Acrobat は、正しく配置されていないドキュメントに対して OCR を実行できない場合があります。文書がまっすぐにスキャンされていない可能性があるため、Acrobat は文書に対して OCR を実行できません。
解決:
スキャンを開始する前に、スキャンする用紙がまっすぐであることを確認してください。歪んだドキュメントを Photoshop で開いてまっすぐにすることもできます。 Photoshop の傾き補正ツールの使い方を説明する投稿です。このツールは、Acrobat で OCR を実行する前に、スキャンした文書をまっすぐにするのに役立ちます。
3]低品質のオリジナル
ファックスなどのソース素材の品質が低い場合、Acrobat はその素材に対して OCR を適切に実行できない場合があります。その場合、より良い品質を追求するか、出力を修正しなければならない危険を冒す必要があります。
解決:
OCR を実行するためのより高品質のソースを入手してください。低品質の文書しかない場合は、OCR を実行して、少なくとも一部が認識されることを期待してから、不足している部分を入力する必要があるかもしれません。
4] グラフィックとフォーム
グラフィックとフォームが混在するドキュメントは、Acrobat の OCR では処理されません。 Acrobat による OCR に使用されるドキュメントには、グラフィックやフォームが混在していてはなりません。混在すると、エラーが発生したり、出力が正しくなくなる可能性があります。
解決:
OCR を実行するドキュメントのプレーン テキスト バージョンを見つけます。また、グラフィックスやフォームを含むドキュメントに対して OCR を実行する必要がある場合もあります。OCR が機能する場合は、出力の修正が必要になる場合があります。
Adobe Acrobat の OCR とは何ですか?
OCR は、Acrobat がピクセルベースのテキストまたは画像を検査するプロセスです。各文字が認識されてテキストに変換されます。 Acrobat は、OCR プロセス中に画像の形状と線の太さを PC にすでにインストールされているフォントと比較します。 OCR スキャン エラーの原因は次のとおりです。
OCR に最適ではないファイル形式は何ですか?
JPEG ファイル形式は、保存するたびに品質が低下する傾向があるため、OCR 用に保存するのには最適ではありません。 JPEG を PDF に変換しても、依然として低品質になる可能性があります。 OCR を実行する場合は、ドキュメントを PDF または TIFF として保存することをお勧めします。