もしWindows 回復環境 (WinRE)動作せず、メッセージが表示される回復環境が見つかりませんでしたWindows 11/10 の場合、この投稿ではその方法を説明します。Windows回復環境を有効にする。場合によっては、Windows RE を起動できないという問題に直面することがあります。理由は複数考えられますが、お使いのコンピューターのどこで Windows RE を利用できるか考えたことはありますか?
Windows 回復環境が機能しない
Windows セットアップ中、Windows は最初に Windows RE イメージ ファイルをインストール パーティションに配置します。 Windows を C ドライブにインストールしている場合は、次の場所から入手できます。C:\Windows\System32\リカバリまたはC:\回復フォルダ。隠しフォルダーです。その後、システムはこのイメージ ファイルを回復ツール パーティションにコピーします。ドライブ パーティションに問題がある場合でも、リカバリを起動できるようになります。
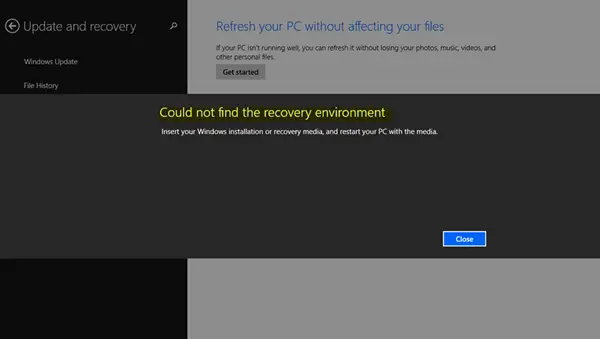
回復環境が見つかりませんでした
このエラーは通常、Windows RE が無効になっているか、Winre.wimファイルが壊れています。したがって、Windows 回復環境が機能していないエラーが発生した場合は、次の方法で修正できます。
1] Windows REまたはWinREを有効にする
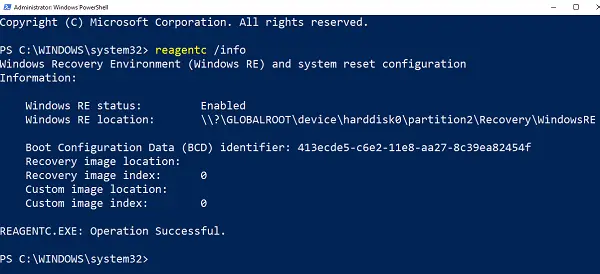
- 管理者権限で PowerShell またはコマンド プロンプトを開きます。
- タイプ
reagentc /infoそして Enter キーを押します。 - 出力にステータスが有効になっていると表示されたら、設定は完了です。
Windows RE を有効にするには、次のように入力します。reagentc /enableそして Enter キーを押します。最後に成功メッセージが表示され、Windows RE が利用可能であることが確認されます。
参考までに、これを無効にするには、次を使用しますreagentc /disable。
2] Winre.wimが破損または欠落しているのを修正
どちらの場合も、Winre.wim の新しいコピーが必要になります。コンピューター上で検索することも、Windows RE が動作している別の同様のコンピューター上でファイルを見つけることもできます。ファイルを見つけたら、別のコンピュータからコピーします。画像パスを新しい場所に設定する必要があります。
次に、次のコマンドを実行して、WIM ファイルのパスを新しい場所に変更します。これらの手順は、Windows RE ファイル パスが通常の場所と異なる場合に使用する必要があります。
Reagentc /setreimage /path C:\Recovery\WindowsRE
ファイルが破損している場合は、別のコンピュータからコピーできます。これを C:\Recovery パスにコピーし、パスを再設定します。必ずパスを確認してくださいreagentc /info指示。
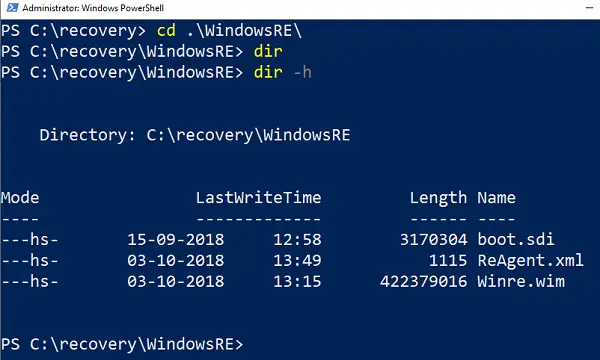
Recovery フォルダーは非表示になっており、Windows ファイル エクスプローラーを使用してアクセスできません。また、その中のWINREフォルダーも非表示になります。これらにアクセスするには、PowerShell またはコマンド プロンプトを使用する必要があります。コピーする前に、そのコンピュータで WINRE を必ず無効にし、後で有効にしてください。
関連している:Windows 回復環境を起動できない
3] Windows ブート ローダー内の無効な WinRE 参照
Windows ブート ローダーは、Windows RE をロードするかどうかを決定します。ローダーが間違った場所を指している可能性があります。
管理者権限で PowerShell を開き、次のコマンドを実行します。
bcdedit /enum all
現在として設定されている Windows ブート ローダー識別子のエントリを探します。
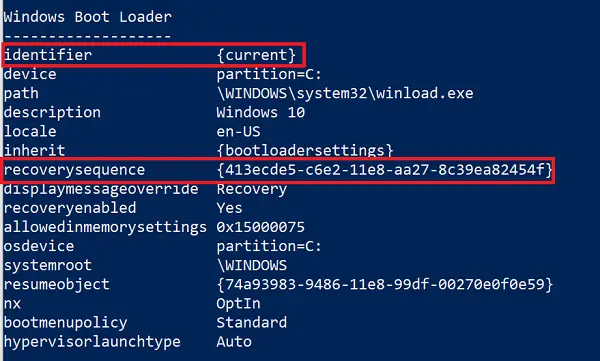
そのセクションで「recoverysequence」を見つけて、GUID をメモします。
再度、結果で、注目された GUID として設定された Windows ブート ローダー識別子を検索します。
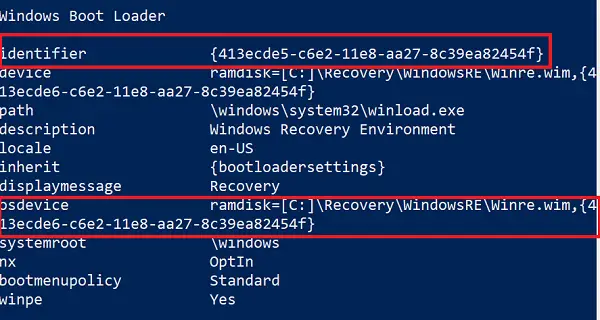
ことを確認してください。デバイスそしてOSデバイス項目は Winre.wim ファイルのパスを示しており、それらは同じです。そうでない場合は、現在の識別子を同じを持つ識別子を指す必要があります。
新しい GUID を見つけたら、次のコマンドを実行します。
bcdedit /set {current} recoverysequence {GUID_which_has_same_path_of_device_and_device}これで問題が解決するかどうかを確認してください。
4]リカバリメディアの作成
ダウンロードWindows ISOファイルを使用してメディア作成ツール。回復ドライブを作成するそして必要なものです。これで問題が解決するかどうかを確認してください。
ではごきげんよう。
REAGENTC.EXE の Windows RE イメージが見つからないエラーを修正
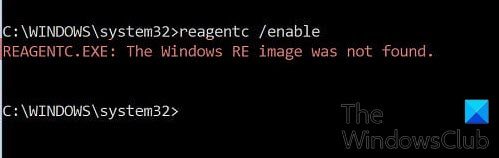
受け取った場合REAGENTC.exe: Windows RE イメージが見つかりませんでしたWindows 回復環境を有効にしようとするとエラー メッセージが表示される場合は、DISMツール破損した可能性のあるシステムイメージを修復し、それが役立つかどうかを確認します。それが役に立たない場合は、次のものを使用する必要があります。PCをリセットするオプション。
読む: REAGENTC.EXE 操作が失敗しました、エラーが発生しました
回復環境に欠けている Windows の詳細オプションを修正する
Windows 11/10 の回復環境に詳細オプションがない場合は、管理者権限でコマンド プロンプトを開き、次のように入力します。reagentc /enableそして Enter キーを押します。最後に成功メッセージが表示され、Windows RE の詳細オプションが利用可能であることが確認されます。